소개
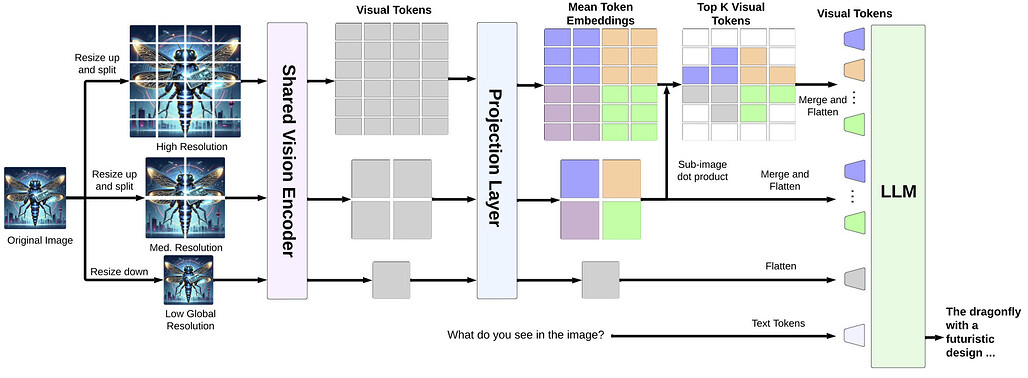
TogetherAI에서 공개한 Dragonfly는 Llama-3 기반의 새로운 비전-언어 아키텍처 모델로, 대규모 멀티모달 모델(LMM)의 발전을 기반으로 한 새로운 아키텍처이다. 고해상도 이미지가 시각적 세부 사항을 이해하는 데 중요한 역할을 하지만, 고해상도 입력은 언어 모델의 컨텍스트 길이를 연장시켜 비효율을 초래하고, 시각적 특성의 복잡성을 증가시켜 더 많은 훈련 데이터나 복잡한 아키텍처를 필요로 한다.
이를 해결하기 위해 Dragonfly는 멀티 해상도 시각 인코딩과 줌인 패치 선택이라는 두 가지 주요 전략을 사용한다. 이러한 전략을 통해 모델은 고해상도 이미지를 효율적으로 처리하면서도 적절한 컨텍스트 길이를 유지할 수 있다. Dragonfly는 여덟 가지 인기 벤치마크에서 경쟁력 있는 성능을 보여주며, 생의학 지침에 대한 미세 조정을 통해 다양한 생의학 작업에서 최첨단 결과를 달성했다.
기존의 비전-언어 모델들과 비교하여, Dragonfly는 다중 해상도 처리와 선택적 패치 분석을 통해 보다 세밀하고 정확한 이미지 이해를 가능하게 한다. Dragonfly는 기존의 대규모 시각-언어 모델(LMM)들과 비교했을 때 고해상도 이미지 처리에 있어 뛰어난 성능을 보여준다. 예를 들어, Path-VQA 데이터셋에서 92.3%의 정확도를 기록하며 Med-Gemini의 83.3%를 능가한다. 또한, 생의학 이미지 캡션 작성 등에서 최고 성능을 기록했다.
주요 특징
- 멀티 해상도 시각 인코딩: 고해상도 이미지를 처리하여 세밀한 시각적 이해를 제공
- 줌인 패치 선택: 효율적인 고해상도 이미지 처리를 지원
- 다양한 벤치마크 성능: 시각적 상식 추론 및 생의학 이미지 분석에서 우수한 성과를 보여줌
- 풍부한 훈련 데이터셋: 550만 개의 일반 도메인 이미지-지시 샘플 및 140만 개의 생의학 도메인 샘플로 구성된 데이터셋을 사용하여 훈련
모델 아키텍처

LLM(대규모 언어 모델)의 발전은 시각-언어 연구에 큰 영향을 미쳤으며, 시각적 표현을 언어 모델에 통합하여 LLM이 새롭게 등장한 시각적 능력을 활용하면서 방대한 언어 지식을 사용할 수 있게 되었다. 시각 특징 정렬은 LLM에 멀티모달 기능을 도입하는 주요 방법 중 하나이다.
이 접근법은 시각 임베딩을 언어 공간으로 매핑하여 시각과 언어를 효과적으로 결합한다. 예를 들어, 사전 훈련된 CLIP 인코더가 생성한 이미지 임베딩을 대규모 언어 모델의 임베딩 공간으로 투영하는 완전 연결 계층을 사용합니다. 유사하게, Perceiver Resampler를 사용하여 시각적 토큰을 언어 도메인으로 통합하는 Flamingo 프레임워크를 채택. 임베딩 정렬 방법을 사용하는 모델은 다양한 벤치마크에서 상당한 성공을 거두며 시각-언어 작업에서 임베딩 정렬의 효과를 입증했다. 그러나 이러한 모델의 한계는 입력 이미지를 고정된 낮은 해상도로 축소해야 한다는 점으로, 이는 시각적 세부 사항을 희생시킵니다. 더 높은 해상도의 시각적 입력이 모델 성능과 세밀한 시각적 내용에 대한 추론을 향상시킬 수 있음을 증명했다.
본래 해상도의 이미지를 더 작고 가변적인 크기의 슬라이스로 세분화하여 이미지 인코더의 전통적인 사전 훈련 구성과 일치시키는 방식을 개선했다. 최근에는 임의의 이미지 해상도를 지원하는 디코더 전용 모델로 사용되어 축소의 단점을 극복했다. Fuyu는 이미지 패치를 트랜스포머의 첫 번째 계층으로 선형 투영하여 이미지 패치 시퀀스를 텍스트 토큰과 유사하게 처리한다. 이러한 개선에도 불구하고 LLM의 맥락적 제약은 여전히 도전 과제로 남아 있다.
이러한 방법은 종종 고해상도 이미지를 인코딩하기 위해 과도한 시각적 토큰을 필요로 하여 비효율성을 초래한다. 반면, Dragonfly는 줌인 패치 선택 방법을 적용하여 고해상도 이미지에서 일부 시각적 토큰을 선택하여 더 효율적으로 처리하면서도 세부적인 시각적 정보를 집중적으로 다룬다. 본 논문은 시각적 지시-튜닝 단계에만 초점을 맞추어 Dragonfly 아키텍처의 설계를 정제하고 최적화하는 것을 목표로 한다.
LLM 및 LMM(대규모 멀티모달 모델)의 발전은 의료 영상, 문헌 및 임상 노트를 통합한 바이오메디컬 시각-언어 모델의 개발에도 큰 진전을 가져왔다. 주목할 만한 예로는 언어 모델링과 마스크드 이미지 채우기 목표를 결합한 멀티태스크 바이오메디컬 기반 모델인 BiomedGPT(Zhang et al., 2023a)가 있다. 유사하게, LLaVA-Med(Li et al., 2024a)는 PubMed와 GPT-4를 활용하여 멀티모달 지시 따르기 데이터셋을 생성하고 LLaVA 모델을 미세 조정한다.
또한, Med-PaLM(Tu et al., 2024), Med-Flamingo(Moor et al., 2023), Med-Gemini(Saab et al., 2024)와 같이 바이오메디컬 애플리케이션을 위해 일반 목적의 LLM이 적응되었다. 이러한 모델은 LMM을 활용하여 특수한 바이오메디컬 과제를 해결할 가능성을 보여준다. 바이오메디컬 작업은 이미지 영역에 대한 강력하고 세밀한 이해 및 추론 능력이 요구된다. 예를 들어, 질환을 식별하는 것은 흉부 X-ray의 특정 영역을 분석하는 것에 달려 있을 수 있다.
해당 논문에서는 Dragonfly 아키텍처를 바이오메디컬 데이터로 미세 조정하여 세밀한 이미지 이해를 평가한다. 140만 개의 고품질 바이오메디컬 시각적 지시 쌍을 통해 우리 모델은 여러 바이오메디컬 작업에서 최첨단 또는 경쟁력 있는 성능을 달성하면서도 다른 기준 모델보다 더 작은 백본을 사용한다.
Dragonfly 모델이 갖는 주요 특징은 다음과 같다
- 드래곤플라이는 멀티 해상도 시각 인코딩과 줌-인 패치 선택이라는 두 가지 주요 전략을 사용한다. 이를 통해 모델은 이미지 영역의 세밀한 디테일을 더 잘 이해하고 상식적인 추론을 제공한다. 모델이 세밀한 이미지 디테일을 캡처하도록 최적화되었음에도 불구하고, 표준 이미지 이해 벤치마크에서 좋은 제로 샷 성능을 보인다.
- Dragonfly 모델은 고해상도 이미지 영역의 세밀한 이해를 필요로 하는 생물의학 작업에서도 이해 및 추론 능력을 입증한다. 140만 개의 생물의학 이미지-텍스트 쌍을 포함한 생물의학 지침 튜닝 데이터셋으로 일반 도메인 모델을 미세 조정하여 Drgaonfly-Med 모델은 시각적 질문 응답, 이미지 캡션 생성, 방사선 보고서 생성 등의 여러 생물의학 벤치마크에서 최고 성능을 달성한다.
여러 생물 의학 벤치마크에서 최첨단 또는 경쟁력 있는 성능을 달성
이미지 캡션 및 방사선 보고서 속 포함 Dragonfly-Med는 Path-VQA 데이터 세트에서 92.3%의 정확도를 달성
IU X-Ray 데이터 세트에서 58.8 CIDEr 점수
Peir Gross 데이터 세트에서 179.9 CIDer 점수
를 각각 획득
Dragonfly 모델 성능 평가

Drgaonfly 모델은 AI2D, ScienceQA, MMMU, MMVet, POPE와 같은 다섯 가지 인기 있는 비전-언어 벤치마크에서 평가되었다. 이들 벤치마크는 강력한 상식적 추론과 세부적인 이미지 이해를 요구한다. 드래곤플라이는 이러한 벤치마크에서 경쟁력 있는 성능을 보였으며, 이미지 영역의 세부 이해와 상식적 추론의 효율성을 입증했다.
Dragonfly-Med (의료용) 모델 성능 평가


Stanford Medicine의 Zou 그룹과 협력하여 Dragonfly 모델에 추가 140만 개의 생물의학 이미지 지침(instruction-following) 데이터로 미세 조정하여 생물의학 버전인 Dragonfly-Med를 개발 및 함께 공개다. Dragonfly-Med는 시각적 질문 응답, 의학 이미지 캡션 생성, 임상 보고서 생성 평가에서 Med-Gemini를 능가하며, 여러 벤치마크에서 최고 성능을 달성했다.
모델을 사용한 추론 코드 예시
다음은 모델을 사용하여 이미지를 처리하는 예제입니다.
import torch
from PIL import Image
from transformers import AutoProcessor, AutoTokenizer
from dragonfly.models.modeling_dragonfly import DragonflyForCausalLM
from dragonfly.models.processing_dragonfly import DragonflyProcessor
device = torch.device("cuda:0")
tokenizer = AutoTokenizer.from_pretrained("togethercomputer/Llama-3-8B-Dragonfly-v1")
clip_processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
image_processor = clip_processor.image_processor
processor = DragonflyProcessor(image_processor=image_processor, tokenizer=tokenizer, image_encoding_style="llava-hd")
model = DragonflyForCausalLM.from_pretrained("togethercomputer/Llama-3-8B-Dragonfly-v1")
model = model.to(torch.bfloat16)
model = model.to(device)
image = Image.open("./test_images/skateboard.png")
image = image.convert("RGB")
images = [image]
text_prompt = "<|start_header_id|>user<|end_header_id|>\n\nSummarize the visual content of the image.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
inputs = processor(text=[text_prompt], images=images, max_length=2048, return_tensors="pt", is_generate=True)
inputs = inputs.to(device)
temperature = 0
with torch.inference_mode():
generation_output = model.generate(**inputs, max_new_tokens=1024, eos_token_id=tokenizer.encode("<|eot_id|>"), do_sample=temperature > 0, temperature=temperature, use_cache=True)
generation_text = processor.batch_decode(generation_output, skip_special_tokens=False)
print(generation_text)
DragonFly 모델 논문
https://arxiv.org/abs/2406.00977?utm_source=pytorchkr&ref=pytorchkr
Dragonfly: Multi-Resolution Zoom Supercharges Large Visual-Language Model
Recent advances in large multimodal models (LMMs) suggest that higher image resolution enhances the fine-grained understanding of image details, crucial for tasks such as visual commonsense reasoning and analyzing biomedical images. However, increasing inp
arxiv.org
DragonFly GitHub 저장소
https://github.com/togethercomputer/Dragonfly?utm_source=pytorchkr&ref=pytorchkr
GitHub - togethercomputer/Dragonfly
Contribute to togethercomputer/Dragonfly development by creating an account on GitHub.
github.com
DragonFly Weight(가중치) 저장소
https://huggingface.co/togethercomputer/Llama-3-8B-Dragonfly-v1?utm_source=pytorchkr&ref=pytorchkr
togethercomputer/Llama-3-8B-Dragonfly-v1 · Hugging Face
Inference API (serverless) does not yet support transformers models for this pipeline type.
huggingface.co
'AI' 카테고리의 다른 글
| MARS5: 혁신적인 음성을 지원하는 New 음성 모델 (0) | 2024.06.17 |
|---|---|
| Stable Cascade : 단계적 접근 방식을 통한 효율적 Text - To - Image 생성 모델 (1) | 2024.02.26 |
| DoRA: 가중치 분해 LoRA (Weight-Decomposed Low-Rank Adaptation) (0) | 2024.02.19 |
| MM-LLMs: 멀티모달 대규모 언어 모델의 최근 발전에 대한 연구 (Recent Advances in MultiModal Large Language Models) (1) | 2024.02.16 |
| MagicVideo-V2, 고품질 비디오 생성 기법 (0) | 2024.01.24 |



